
On the Fly Neo4j Exercise
neo4j databases easi It’s been over a month since I was doing a Neo4j-oriented project. On another project today, some set data was provided to me in a CSV file. The goal was to come up with a decent visualization of all the sets and their intersections… I thought it might be helpful to a graph visualization, then realized it would be a perfect excuse to make sure I’m not getting rusty with Neo4j and Cypher.
The CSV file was not ideal. I saw this as an opportunity! To make things interesting, instead of doing any preprocessing with command line tools or in Python, my mission was to do any and all of this using only Cypher and APOC. Naturally, this means that the code snippets below ought provide for a great overview of getting started with Neo4j. Ultimately, it was good experience coming up with a graph schema and ingestion strategy on the fly, despite the resulting graph visualization not being such a great viz.
Some Setup Stuff
Below, I use Neo4j Desktop (Neo4j 3.5.3). My advice is to create or use a “sandbox” database where you don’t mind deleting everything and playing around.
In Neo4j Desktop, navigate to your sanbox database, then click on “Manage” and find the
“Settings” tab. About 25 lines down, you should see a parameter related to LOAD CSV that
restricts data ingestion to files found only in a very specific directory. This is usually
good for security reasons, but since this is a toy project, just comment it out so you can
ingest CSV data from any directory.
# This setting constrains all `LOAD CSV` import files to be under the `import` directory. Remove or comment it out to
# allow files to be loaded from anywhere in the filesystem; this introduces possible security problems. See the
# `LOAD CSV` section of the manual for details.
#dbms.directories.import=import
Now start the database and open Neo4j Browser.
Pro Tip: In Neo4j Browser, click on the “Settings” icon on the lefthand toolbar. Click on the checkbox setting that reads “Enable multi statement query editor”. This enables your query editor can take multiple semi-colon-separated Cypher commands in a row.
The CSV File
Imagine a CSV file that looks something like I’ve mapped out below. It’s not the data I worked with, but close enough – at the least, there is enough there to simulate today’s experiment. I found that trying to visualize anything beyond doublets (intersections of of two sets) just looks like spaghetti, so the data below is enough!
head -n 15 file.csv
Name,a,b,c,d,Set Size,Search Terms
null,0,0,0,0,40847,some string of info about full set
"""a""",1,0,0,0,11183,some string of info about how to extract set a
"""b""",0,1,0,0,792,some string of info about how to extract set b
"""c""",0,1,0,0,27,some string of info about how to extract set c
"""d""",0,1,0,0,486,some string of info about how to extract set d
"""a"" ""b""",1,1,0,0,144,some info about intersection of a and b
"""a"" ""c""",1,1,0,0,2,some info about intersection of a and c
"""a"" ""d""",1,1,0,0,52,some info about intersection of a and d
"""b"" ""c""",1,1,0,0,3,some info about intersection of b and c
"""b"" ""d""",1,1,0,0,7,some info about intersection of b and d
"""c"" ""d""",1,1,0,0,1,some info about intersection of c and d
"""a"" ""b"" ""c""",1,1,1,0,0,some info about the abc triplet
"""a"" ""b"" ""d""",1,1,0,1,2,some info about the abd triplet
"""b"" ""c"" ""d""",0,1,1,1,1,some info about the bcd triplet
You can see things are not ideal:
- column names with spaces
- names with extraneous quotations
These are trivial fixes, but help display some Cypher functionality below.
The Graph Schema
So what is this data anyway?
Columns a, b, c, and d are binary: a value of 1 says to take an intersection with the
associated set. For example (a,b,c,d)=(1,0,1,0) is equivalent to FullSet INTERSECT set(a) INTERSECT set(b).
There are likely many ways you can turn this data into labels, nodes, and relationships. Here is what I devised:
(:FullSet) -[:792]-> (:Subset {name, search}) -[:40]-> (:SubsetIntersection {name, search})
Basically, there is a top-level (:FullSet) node, which is related to (:Subset) nodes by relationships whose type is the cardinality of the subset. This means that relationship types needed to be named dynamically in the code below, which motivated the use of APOC. Note that dynamic relationship types like this might be horrible for something like production-level code in a social network app, but the main motivator for this project was to get a decent graph visualization out of it – and by naming the relationship types with the subset cardinality, we are ensured that this info shows up on the stock visualization in Neo4j Browser. This is key since this info is literally showing the strength of the relationship between the parent and child node.
The Code
// DELETE AND START FROM SCRATCH
MATCH (n) DETACH DELETE n;
// Create Constraints
CREATE CONSTRAINT ON (subset:Subset) ASSERT subset.name is UNIQUE;
CREATE CONSTRAINT ON (intersection:SubsetIntersection) ASSERT intersection.name is UNIQUE;
// [1] Create
// -- note that %20 is code for a space, which I have to use b/c directories
// in the file path unfortunately have spaces!!!!!
:param filename: "file:///Users/firstLast/Annoying%20-%20Directory%20Name/path/to/file.csv"
// Create full set node
LOAD CSV WITH HEADERS FROM $filename AS LINE
WITH toInteger(LINE.a) AS a,
toInteger(LINE.b) AS b,
toInteger(LINE.c) AS c,
toInteger(LINE.d) AS d,
toInteger(LINE.`Set Size`) AS size,
LINE.`Search Terms` AS search
WHERE a+b+c+d = 0
MERGE (:FullSet {name: "Full Set", search: search, size: size});
// Create subset nodes (subsets)
LOAD CSV WITH HEADERS FROM $filename AS LINE
WITH replace(LINE.Name,'"','') as name,
toInteger(LINE.a) AS a,
toInteger(LINE.b) AS b,
toInteger(LINE.c) AS c,
toInteger(LINE.d) AS d,
LINE.`Set Size` AS size,
LINE.`Search Terms` AS search
WHERE a+b+c+d = 1
MERGE (fullset:FullSet {name: "Full Set"})
MERGE (subset:Subset {name: name, search: search})
WITH fullset, subset, size AS rlnshp
CALL apoc.create.relationship(fullset, rlnshp, {}, subset) YIELD rel
REMOVE rel.null;
// Create Subset Intersections
LOAD CSV WITH HEADERS FROM $filename AS LINE
WITH LINE.Name as name,
toInteger(LINE.a) AS a,
toInteger(LINE.b) AS b,
toInteger(LINE.c) AS c,
toInteger(LINE.d) AS d,
LINE.`Set Size` AS size,
LINE.`Search Terms` AS search
WHERE a+b+c+d = 2
AND toInteger(size) > 0
WITH size, search,
split(replace(name,'" "','"'),'"') AS subset_list_temp
WITH size, search,
filter(x in subset_list_temp WHERE x <> '') AS subset_list
WITH size, search,
subset_list[0] AS name0, subset_list[1] AS name1,
subset_list[0]+' & '+subset_list[1] AS dname
MERGE (intersection:SubsetIntersection {name: dname, search: search})
MERGE (subset0:Subset {name: name0})
MERGE (subset1:Subset {name: name1})
WITH subset0, subset1, intersection, size as rlnshp
CALL apoc.create.relationship(subset0, rlnshp, {}, intersection) YIELD rel as rel0
CALL apoc.create.relationship(subset1, rlnshp, {}, intersection) YIELD rel as rel1
REMOVE rel1.null;
RETURN "DONE!";
The Figure
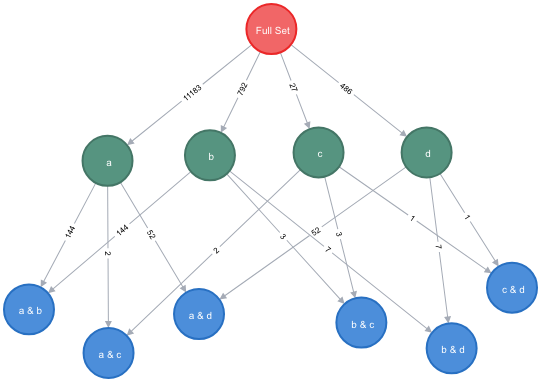
The Breakdown
Have to finish this later………
NOTE 1:
It’s necessary to end Cypher query w/ RETURN or update command (like REMOVE),
so the REMOVE temp.null command actually does nothing, but must be there
for the query to not crash… Why? It’s kind of a weird oopsy-daisy from
mixing Cypher w/ APOC…
NOTE 2: Unlike the simple relationship-type command, this dynamic command will create new relationship each time it is run, independent of whether or not it already exist!!! So beware.